MKR¶
Introduction¶
Title: Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation
Authors: Hongwei Wang, Fuzheng Zhang, Miao Zhao, Wenjie Li, Xing Xie, Minyi Guo
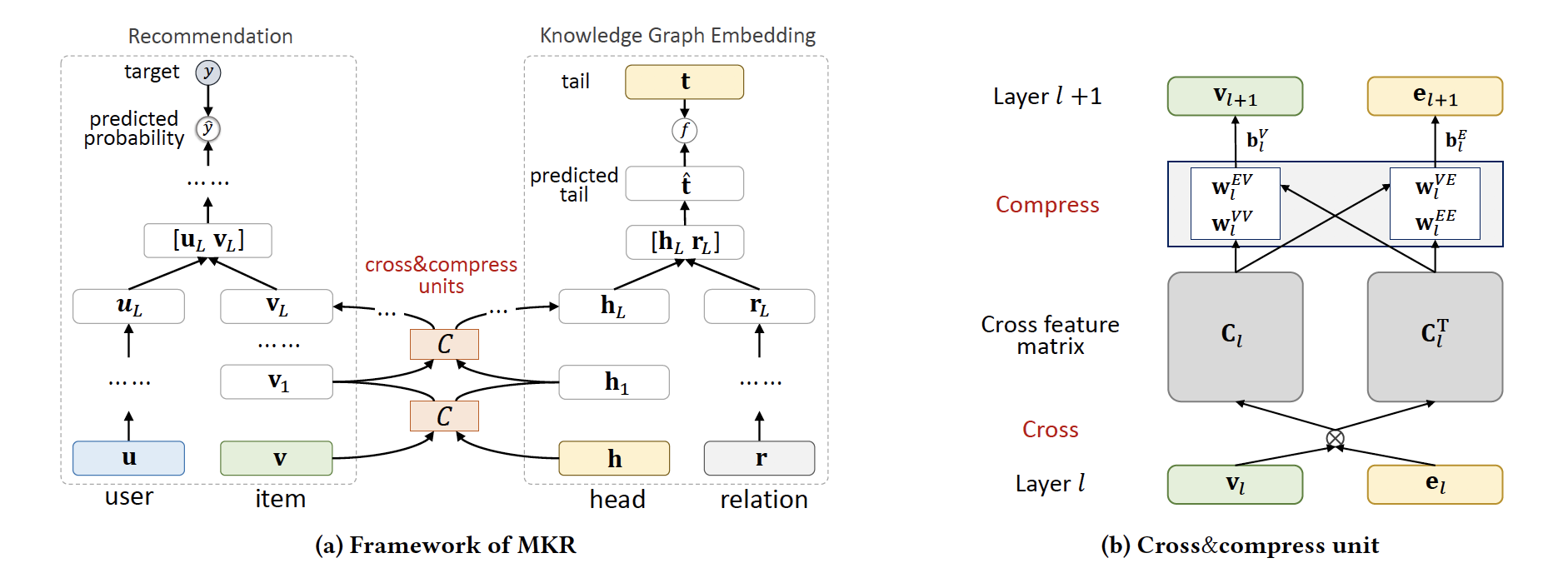
Abstract: Collaborative filtering often suffers from sparsity and cold start problems in real recommendation scenarios, therefore, researchers and engineers usually use side information to address the issues and improve the performance of recommender systems. In this paper, we consider knowledge graphs as the source of side information. We propose MKR, a Multi-task feature learning approach for Knowledge graph enhanced Recommendation. MKR is a deep end-to-end framework that utilizes knowledge graph embedding task to assist recommendation task. The two tasks are associated by crosscompress units, which automatically share latent features and learn high-order interactions between items in recommender systems and entities in the knowledge graph. We prove that crosscompress units have sufficient capability of polynomial approximation, and show that MKR is a generalized framework over several representative methods of recommender systems and multi-task learning. Through extensive experiments on real-world datasets, we demonstrate that MKR achieves substantial gains in movie, book, music, and news recommendation, over state-of-the-art baselines. MKR is also shown to be able to maintain satisfactory performance even if user-item interactions are sparse.
Running with RecBole¶
Model Hyper-Parameters:
embedding_size (int): The embedding size of users and items. Defaults to64.kg_embedding_size (int): The embedding size of entities, relations. Defaults to64.low_layers_num (int): The number of low layers. Defaults to1.high_layers_num (int): The number of high layers. Defaults to1.kge_interval (int): The number of steps for continuous training knowledge related task. Defaults to3.use_inner_product (bool): Whether to use inner product to calculate scores. Defaults toTrue.reg_weight (float): The L2 regularization weight. Defaults to1e-6.dropout_prob (float): The dropout rate. Defaults to0.0.
A Running Example:
Write the following code to a python file, such as run.py
from recbole.quick_start import run_recbole
run_recbole(model='MKR', dataset='ml-100k')
And then:
python run.py
Tuning Hyper Parameters¶
If you want to use HyperTuning to tune hyper parameters of this model, you can copy the following settings and name it as hyper.test.
learning_rate choice [0.01,0.005,0.001,0.0005,0.0001]
low_layers_num choice [1,2,3]
high_layers_num choice [1,2]
l2_weight choice [1e-6,1e-4]
kg_embedding_size choice [16,32,64]
Note that we just provide these hyper parameter ranges for reference only, and we can not guarantee that they are the optimal range of this model.
Then, with the source code of RecBole (you can download it from GitHub), you can run the run_hyper.py to tuning:
python run_hyper.py --model=[model_name] --dataset=[dataset_name] --config_files=[config_files_path] --params_file=hyper.test
For more details about Parameter Tuning, refer to Parameter Tuning.
If you want to change parameters, dataset or evaluation settings, take a look at