RaCT¶
Introduction¶
Title: Towards Amortized Ranking-Critical Training for Collaborative Filtering
Authors: Sam Lobel, Chunyuan Li, Jianfeng Gao, Lawrence Carin
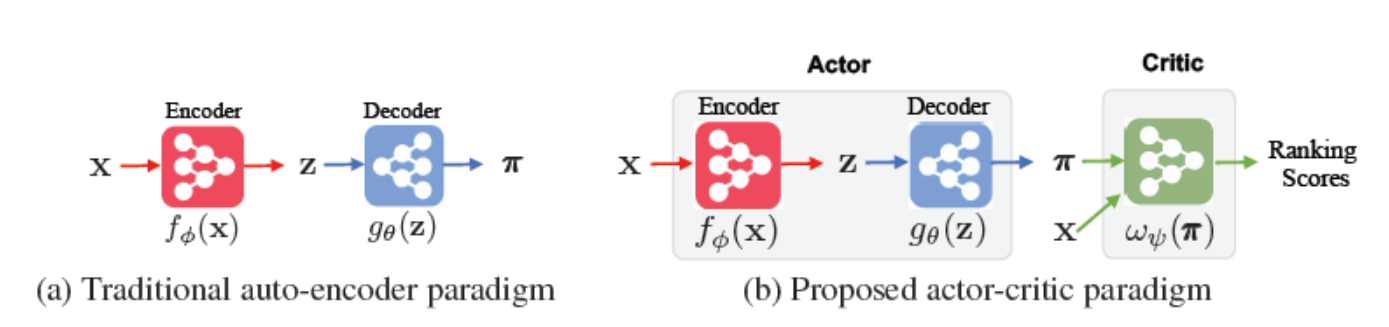
Abstract: Collaborative filtering is widely used in modern recommender systems. Recent research shows that variational autoencoders (VAEs) yield state-of-the-art performance by integrating flexible representations from deep neural networks into latent variable models, mitigating limitations of traditional linear factor models. VAEs are typically trained by maximizing the likelihood (MLE) of users interacting with ground-truth items. While simple and often effective, MLE-based training does not directly maximize the recommendation-quality metrics one typically cares about, such as top-N ranking. In this paper we investigate new methods for training collaborative filtering models based on actor-critic reinforcement learning, to directly optimize the non-differentiable quality metrics of interest. Specifically, we train a critic network to approximate ranking-based metrics, and then update the actor network (represented here by a VAE) to directly optimize against the learned metrics. In contrast to traditional learning-to-rank methods that require to re-run the optimization procedure for new lists, our critic-based method amortizes the scoring process with a neural network, and can directly provide the (approximate) ranking scores for new lists. Empirically, we show that the proposed methods outperform several state-of-the-art baselines, including recently-proposed deep learning approaches, on three large-scale real-world datasets.
Running with RecBole¶
Model Hyper-Parameters:
latent_dimendion (int): The latent dimension of auto-encoder. Defaults to256.mlp_hidden_size (list): The MLP hidden layer. Defaults to[600].dropout_prob (float): The drop out probability of input. Defaults to0.5.anneal_cap (float): The super parameter of the weight of KL loss. Defaults to0.2.total_anneal_steps (int): The maximum steps of anneal update. Defaults to200000.critic_layers (list): The layers of critic network. Defaults to[100,100,10].metrics_k (int): The parameter of NDCG for critic network training. Defaults to100.train_stage (str): The training stage. Defaults to'actor_pretrain'. Range in['actor_pretrain', 'critic_pretrain', 'finetune'].pretrain_epochs (int): The pretrain epochs of actor pre-training or critic-pretraining. Defaults to ‘150’.save_step (int): Save pre-trained model everysave_steppre-training epochs. Defaults to10.pre_model_path (str): The path of pretrained model. Defaults to''.
A Running Example:
Run actor pre-training. Write the following code to run_actor_pretrain.py
from recbole.quick_start import run_recbole
config_dict = {
'train_stage': 'actor_pretrain',
'pretrain_epochs': 150,
'train_neg_sample_args': None,
}
run_recbole(model='RaCT', dataset='ml-100k',
config_dict=config_dict, saved=False)
And then:
python run_actor_pretrain.py
Run critic pre-training. Write the following code to run_critic_pretrain.py
from recbole.quick_start import run_recbole
config_dict = {
'train_stage': 'critic_pretrain',
'pretrain_epochs': 50,
'pre_model_path': './saved/RaCT-ml-100k-150.pth',
'train_neg_sample_args': None,
}
run_recbole(model='RaCT', dataset='ml-100k',
config_dict=config_dict, saved=False)
And then:
python run_critic_pretrain.py
Run fine-tuning. Write the following code to run_finetune.py
from recbole.quick_start import run_recbole
config_dict = {
'train_stage': 'finetune',
'pre_model_path': './saved/RaCT-ml-100k-50.pth',
'train_neg_sample_args': None,
}
run_recbole(model='RaCT', dataset='ml-100k',
config_dict=config_dict)
And then:
python run_finetune.py
Notes:
Because this model is a non-sampling model, so you must set
train_neg_sample_args=Nonewhen you run this model.In the actor pre-training and critic pre-training stage, the pre-trained model would be saved , named as
RaCT-[dataset_name]-[pretrain_epochs].pth(e.g. RaCT-ml-100k-100.pth) and saved to./saved/.In the fine-tuning stage, please make sure that the pre-trained model path is existed.
Because this model needs different learning rates in different stages, we suggest setting
learning_rateat0.0001in the critic pre-training stage and settinglearning_rateat0.000002in the fine-tuning stage.
Tuning Hyper Parameters¶
If you want to use HyperTuning to tune hyper parameters of this model, you can copy the following settings and name it as hyper.test.
learning_rate choice [0.01,0.005,0.001,0.0005,0.0001]
latent_dimension choice [128,200,256,400,512]
Note that we just provide these hyper parameter ranges for reference only, and we can not guarantee that they are the optimal range of this model.
Then, with the source code of RecBole (you can download it from GitHub), you can run the run_hyper.py to tuning:
python run_hyper.py --model=[model_name] --dataset=[dataset_name] --config_files=[config_files_path] --params_file=hyper.test
For more details about Parameter Tuning, refer to Parameter Tuning.
If you want to change parameters, dataset or evaluation settings, take a look at